
Blackbit Data Director for Pimcore
The interface between Pimcore and your data sources
Blackbit Data Director für Pimcore – Pimcore Imports, Exports, Automation
Pimcore plugin to optimize Pimcore concerning all PIM-related features, especially imports, exports, automation, workflows.
- import XML, JSON, CSV, Excel and other data sources to Pimcore data objects, assets and documents
- export data from Pimcore to XML, JSON, CSV, Excel and other formats,
create REST APIs for writing or reading Pimcore data, - push data to external systems (shops, websites, etc.),
- create automations and workflows within Pimcore and
- make daily tasks in Pimcore much more efficient.
Find Further Information Here

With the Pimcore Data Director Bundle from Blackbit, you can import XML, CSV, JSON and Excel files into Pimcore objects, assets and documents. You can also export feeds and create a REST API without any programming.
In the Pimcore admin panel, you define which data is to be extracted from the import source and assign it to the object fields of your Pimcore objects. All Pimcore data types are supported for the import. It is also possible to import assets and documents.
During the import, data can be modified and adapted to your data model. The Pimcore Data Director provides extensive functions and a convenient user interface and is a proven basis for importing structured data into Pimcore objects, assets and documents.
The Data Director reduces the effort involved in programming individual interfaces and shortens the time it takes to get your Pimcore project up and running.
How the Import of Data Works with the Pimcore Data Director
The Data Director has proven itself in many e-commerce, PIM and master data management projects and has been developed to meet the requirements of our customers.
The aim of the Data Director is to import information from upstream systems into Pimcore objects, enrich it with additional information if necessary and publish it via Pimcore itself or via a downstream system such as an online store.
The import always takes place in two steps.

Step 1: Parsing the Source File, Importing the Data into a Flat Database Table
In the first step, an intuitive user interface is used to determine which columns of a CSV file or which attributes of an XML are to be imported into Pimcore.
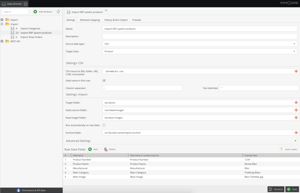
A preview shows directly whether the entries are correct. The import reads the data into an "intermediate table" so that users can see which data has been imported from the upstream system before it is processed further in the next step.
Step 2: Mapping Attributes Using Drag-and-Drop
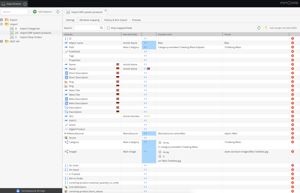
In the second step, the information from the intermediate table is assigned to the object attributes of the customized classes defined in Pimcore using drag-and-drop.
For this purpose, all fields of the target class are listed in the attribute mapping panel. You can assign the raw data field to be used from step 1 to each field.
One or more key attributes are defined so that the process can be repeated and the objects can be updated in Pimcore. If several fields are defined as key fields, they are linked with AND so that objects are only updated if all key fields match the assigned raw data fields.
In the settings of the data port panel under "Advanced options", you can specify the import mode, available are
- Create and edit objects
- Create new objects, do not edit existing ones
- Edit existing objects, do not create new objects
Modifications can also be made to the source data during attribute mapping. A callback function can be specified for each field mapping, which, for example, performs drawing operations and calculations based on several imported attributes or attributes that already exist in the current object.

Data Director Video
Here you can see the presentation of our Tribe Lead Jan Walther about the Pimcore Data Director on the occasion of Pimcore Inspire 2021.
Pimcore Tutorials on the Data Director
In our Knowledge Base you will find a series of video tutorials that explain the possibilities of the Pimcore Data Director in detail.

Test the Pimcore Data Director
Further Highlights at a Glance
File-based Imports
(monitoring of a directory and automatic import of new files), e.g. for
- automatic asset imports into Pimcore (e.g. from a network drive)
- Automatic assignment of assets to Pimcore objects based on the file name
Import of Multiple Files
(CSV, XML, Excel) from a source directory with automatic deduplication
Import From A URL As A Data Source
Import of Data From Pimcore Objects:
- Migration of data from one object field to another without data loss
- Dynamic mass data editing, which is not possible in the Pimcore Grid (e.g. increase prices by 10%)
Import of Documents (Filling the Editables)
Starting Imports Via REST API
Generating Response Documents, e.g.
- Success status of the imported objects
- Recording import errors
- Calling up another import that is dependent on the current import
- Creating CSV, XML, JSON documents that can be used by other systems as an import source
- Response documents for single-page applications/PWA frontend requests
Skipping Data Records From the Import Source
(e.g. if data is missing or its quality is insufficient)
Simple Import of Relations
Import of Object Hierarchies/Object Trees
- Specification of the parent element possible
- Option to optimize inheritance (data is entered as high up in the object hierarchy as possible)
Translation of Texts (Via DeepL or AWS API)
Support of All Pimcore Data Types (Incl. Relations With Metadata, Object Modules, Field Collections, etc.):
Optimized performance:
- if the source data has not changed, the import of the data record can be skipped
- If object data is not changed during import, it does not need to be saved
Possibility to undo imports:
- If an error has crept in during attribute mapping and several thousand objects may have been filled with incorrect data as a result, the change can be rewound - in this case, only the fields mapped in the import are undone, only for the objects changed in the import - a major advantage over importing a complete backup
You can also see exactly how this works in our documentation.
Creating Relevant Added Value With Pimcore
We develop e-commerce solutions, booking and event platforms, PIM systems and corporate websites. Find out all about Pimcore and our services as a Platinum Partner and Enterprise Subscription Integrator.
Pimcore, as a comprehensive open source platform, offers unique solutions in the field of data and experience management.
Pimcore offers out-of-the-box open source digital asset management that can be accessed via webdav or web.
As a content management system (CMS), Pimcore allows you to create and manage content centrally and edit it directly on your website.
Produce flyers, product sheets, price lists or complete product catalogs conveniently via the Pimcore backend.
Automated and database-supported creation of catalogs and price lists using Adobe InDesign.
Blackbit has over twenty years of experience in hosting and managing e-commerce systems.