
Our developers have invested a lot of time in new optimisations to offer you an improved user experience when using the Data Director in the current version. Our powerful import and export bundle comes in version 3.3 with the following new or revised functions and features:

Summary of data port runs.
There is now a summary window for manually executed imports and exports. This provides a graphical user interface that shows what happened during the imports and exports. It contains the progress, the changed data (including the change view) and errors (if any occurred):
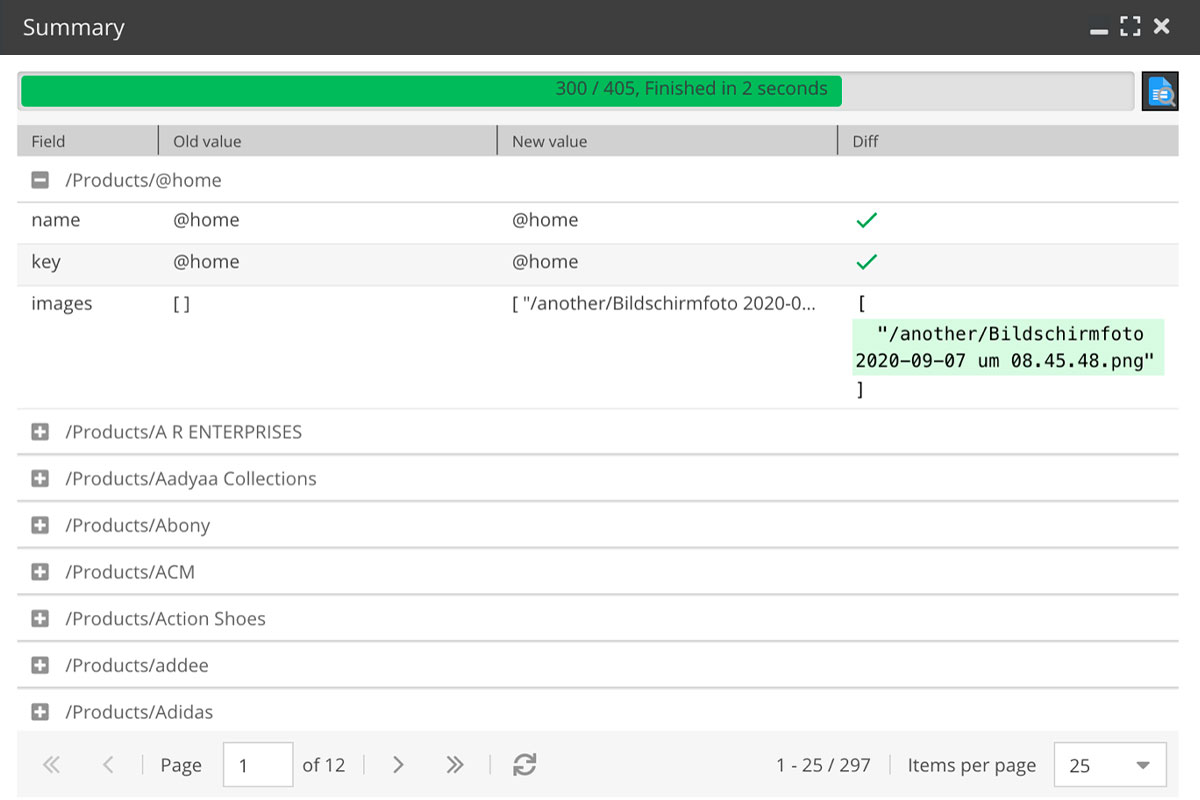
This allows non-technical people to run Dataports and check that everything has been done properly.
Intelligent logging
For non-manually started imports and exports (e.g. cronjob runs, REST API, event-driven dataport runs), the logger checks for errors (but also buffers less serious logs). Only if an error occurs are the buffered logs written. If the run is completed successfully without errors, warnings or notices, no log file is saved. This reduces the storage space for the log files and thus enables frequent applications such as REST API interfaces for real website users.
In addition, this version implements lazy logging: Log information is only generated when the log is actually to be written. Previously, the log was generated even if the log was not saved at the end at all (e.g. debug logs) - but for log levels that are not logged anyway, all the effort for generating the log information (e.g. object serialisation, JSON encoding, etc.) was superfluous.
More efficient queue processor
Imports for the same dataport but different import resources are now executed in parallel. As a result, automatic dataports (e.g. data quality) are executed much faster for bulk imports: The queue processor now adjusts the number of parallel processes more frequently. In addition, the number of maximum parallel processes is stored in the site settings instead of in the cache. This prevents the number from being reset when the cache is emptied. Useful side effect: It is possible to manually increase the number of maximum parallel processes.
UI changes
Dataport tree
- Marking dataports that have not been used for more than 14 days to help clean up old dataports.
- Marking dataports with errors on recent runs in red to immediately identify which dataports are causing problems.
- Roles that have a dataport as a favourite in the dataport tree context menu are displayed hierarchically to give a better overview.
- For grouping dataports with a common prefix, the case of the first letter is ignored.
Dataport configuration
- Mass editing support for raw data fields.
Attribute mapping
- Better preview and explanation when the key field returns an array.
- Support mapping of creationDate, modificationDate for asset imports.
- Does not show individual object brick fields if there are more than 50. In this case, mapping is only possible via the object brick container, otherwise the load time is too long (nevertheless, further optimisation of the attribute mapping load time is being worked on).
Preview panel
- Multiple selection support for processing multiple raw data items (for testing).
- Multiple selection support for opening multiple items by reference to key fields.
- Highlighting of data where the search term is found instead of hiding columns where the search term is not found.
Object edit box/grid box
- Display available exports/imports for an object in the object edit toolbar.
- Grid export: Always set "Content-Disposition: attachment", as grid exports are always executed in the same window as Pimcore. If the result callback function did not create a result document (but e.g. only queued another dataport), an empty page was opened in the Pimcore tab. Instead, there is now always a download for grid exports: If the dataport does not generate a response document, a dummy document with "Dataport executed successfully" is provided.
Other changes
- XML imports: Logging of XML errors.
- Support for importing from FTPS resources.
- Prevention of misuse of programmatically started dataports:
When dataports are started programmatically, it could happen that too many processes were executed and the server crashed. Now it is first checked whether and how many processes are running on a particular dataport (relative to the CPU count). If there are too many, new processes are automatically added to the queue instead of being executed.
This can happen, for example, if another dataport is triggered by the result callback function via Cli::execInBackground('bin/console dd:complete 123') - actually, the "start dependent dataport" template prevents this. If developers did not use this template, they could fall into this trap. However, this danger is now averted. - Support of the import into the field type "block".
- Support for importing strings that look like JSON but should be handled without parsing, e.g. [100.00] must not be converted to [100].
- Automatic installation of migrations in the maintenance script.
This makes updating easier because you no longer have to do the migrations manually. - Automatic deletion of elements in the queue that are older than three days. This is usually caused by incorrect result callback functions via the "start dependent dataport" command.
- Data Query Selectors: Support for searching for assets via metadata fields.
- Improved recognition of the value and unit of quantity value fields when specified as strings. The following strings have been successfully tested to be imported into quantity value fields:
- 1,23m
- 1,23 m
- -10°C
- 10°C
- 10° C
- 12 revolutions per minute
- € 12
- If there were queuing processes that referred to deleted dataport resource IDs (e.g. by deleting raw data in the preview panel), the corresponding SQL conditions were created as independent dataport resources. This could result in a large number of dataport resources, so that all had to be checked before an object was saved. This slowed down the storage processes.
- Prevented a false email notification "Queue processor could not be started".
- Use of league/flysystem-sftp-v3 instead of league/flysystem-sftp → PHP 8.1 compatibility.
- Asset imports: avoidance of an error when importing folders.
- Support for the special raw data field selector "__count" to determine the number of records in the current import file.
- Tagging of elements in case of import errors to facilitate the search for import problems.
- Support of the selector "__all" for XML resources to get complete raw data in a raw data field.
- Provision of a currency conversion service when importing quantity value fields with the option "Automatically create non-existing units".
- Support for automatic execution of dataports without a data source (e.g. as pseudo cronjobs).
- Addition of a callback function template for the initialisation function to limit the frequency of dataports, e.g. execution only every x hours (pseudo cronjob).
- Support for CORS preflight requests for REST API endpoints.
Our Data Director Tutorials
Further helpful tips on using the Pimcore Data Director are provided by the detailed tutorials in the Blackbit Academy.
Not familiar with the Data Director yet?
Curious about our Pimcore Import and Export Bundle? Then inform yourself in our shop and about the import and export bundle for Pimcore.
We will be happy to show you in an individual demo which possibilities the Data Director offers you. Contact us now!
