Pimcore Data Director
Die Schnittstelle zwischen Pimcore und Ihren Datenquellen


Pimcore Data Director Bundle
Mit dem Pimcore Data Director Bundle von Blackbit importieren Sie XML-, CSV-, JSON- und Excel-Dateien in Pimcore-Objekte, -Assets und -Dokumente. Sie können auch Feeds exportieren und eine REST-API ohne jegliche Programmierung erstellen.

Im Pimcore Adminpanel legen Sie fest, welche Daten aus der Import-Quelle extrahiert werden sollen und ordnen diese den Objektfeldern Ihrer Pimcore-Objekte zu. Hierbei werden sämtliche Pimcore-Datentypen für den Import unterstützt. Auch der Import von Assets und Dokumenten ist möglich.
Während des Imports können Daten modifiziert und an Ihr Datenmodell angepasst werden. Der Pimcore Data Director stellt umfangreiche Funktionen und ein komfortables Benutzerinterface zur Verfügung und ist eine bewährte Basis für den Import strukturierter Daten in Pimcore-Objekte, -Assets und -Dokumente.
Der Data Director senkt den Aufwand für die Programmierung individueller Schnittstellen und verkürzt die Zeit bis zur Inbetriebnahme Ihres Pimcore-Projektes.
So funktioniert der Import von Daten mit dem Pimcore Data Director
Der Data Director hat sich in vielen E-Commerce-, PIM- und Master-Data-Management-Projekten bewährt und ist entsprechend den Anforderungen unserer Kunden entwickelt worden.
Ziel des Data Directors ist es, Informationen aus vorgelagerten Systemen in die Objekte von Pimcore zu importieren, dort gegebenenfalls mit weiteren Informationen anzureichern und über Pimcore selbst bzw. über ein nachgelagertes System wie zum Beispiel einen Online-Shop zu veröffentlichen.
Der Import läuft stets in zwei Schritten ab:
Schritt 1: Parsen der Quelldatei, Import der Daten in eine flache Datenbanktabelle
Im ersten Schritt wird mit Hilfe eines intuitiven Benutzerinterfaces festgelegt, welche Spalten einer CSV-Datei bzw. welche Attribute einer XML in Pimcore importiert werden sollen.
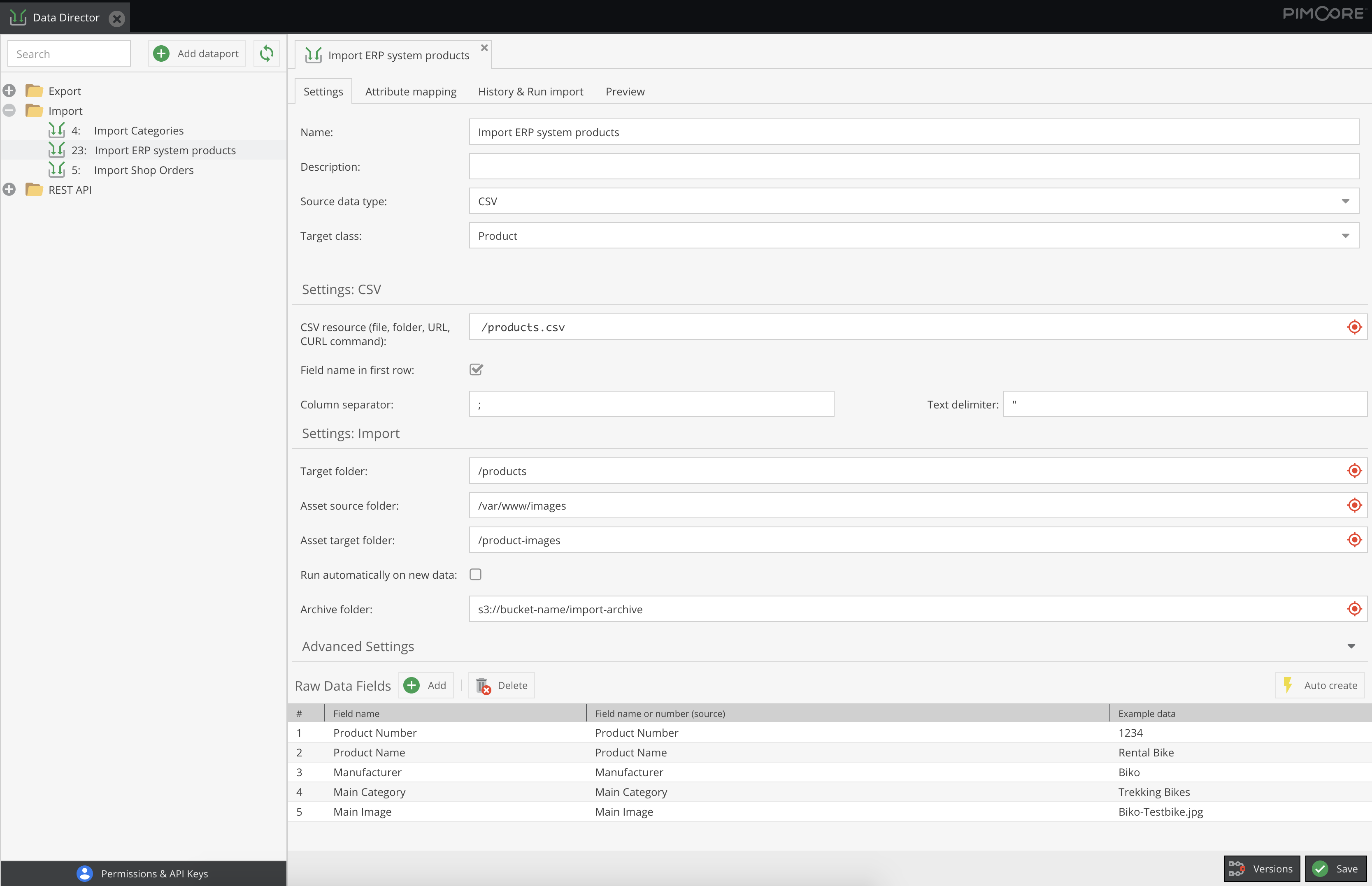
Eine Vorschau zeigt direkt an, ob die Eingaben richtig sind. Der Import liest die Daten in eine „Zwischentabelle“ ein, sodass der Anwender hier nachsehen kann, welche Daten aus dem vorgelagerten System importiert wurden, bevor diese im nächsten Schritt weiterverarbeitet werden.
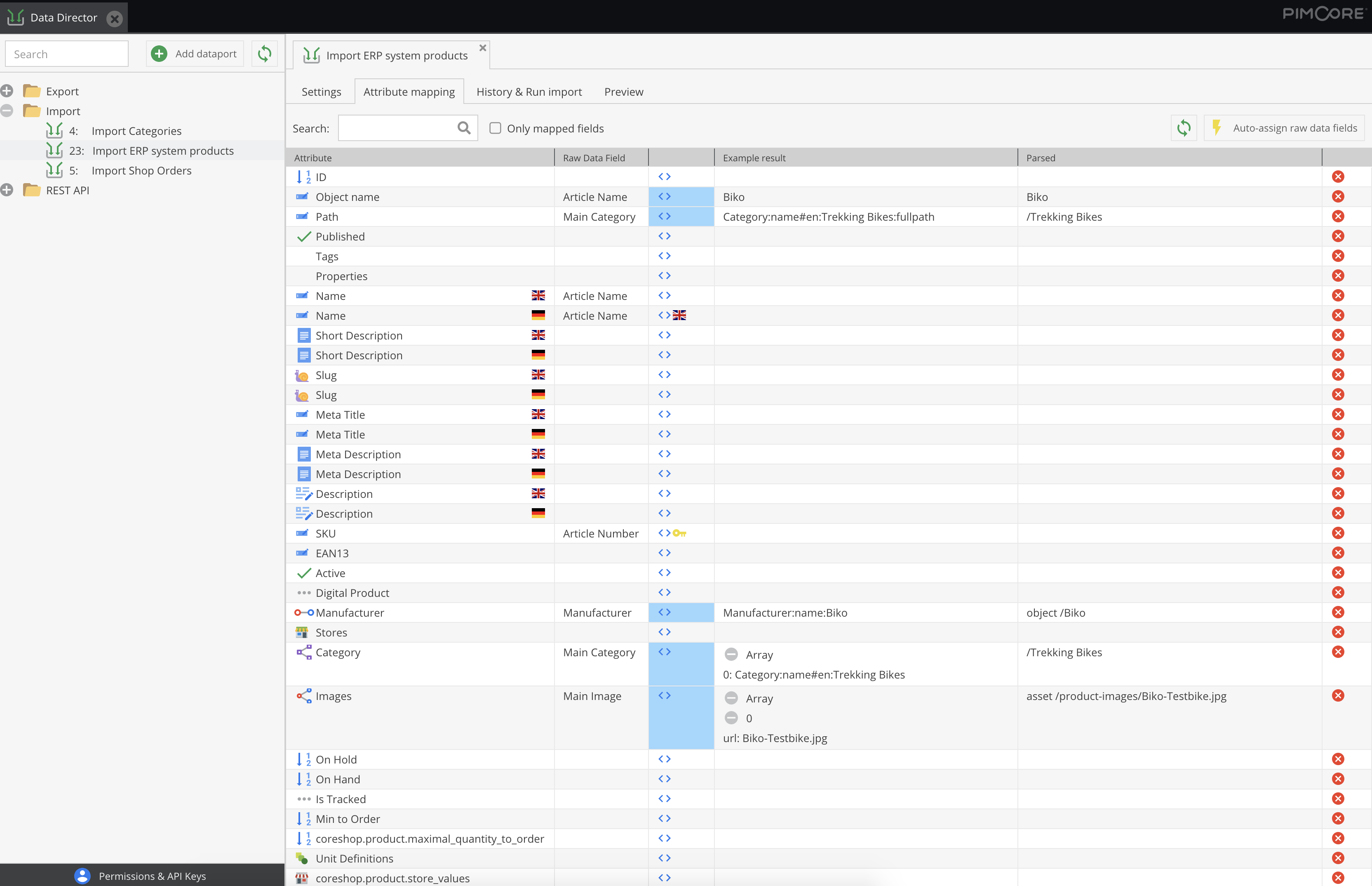
Schritt 2: Mapping von Attributen per Drag-and-Drop
Im zweiten Schritt werden die Informationen aus der Zwischentabelle den Objektattributen der in Pimcore kundenindividuell definierten Klassen per Drag-and-Drop zugeordnet.
Hierzu werden im Attribut-Mapping-Panel alle Felder der Zielklasse aufgelistet. Jedem Feld können Sie das zu verwendende Rohdatenfeld aus Schritt 1. zuweisen.
Hierbei werden ein oder mehrere Schlüsselattribute festgelegt, sodass der Vorgang wiederholt und die Objekte in Pimcore aktualisiert werden können. Wenn mehrere Felder als Schlüsselfelder festgelegt sind, werden sie mit UND verknüpft, sodass Objekte nur aktualisiert werden, wenn alle Schlüsselfelder mit den zugewiesenen Rohdatenfeldern übereinstimmen.
In den Einstellungen des Datenport-Panels unter „Erweiterte Optionen“ können Sie den Importmodus festlegen, verfügbar sind
- Objekte erstellen und bearbeiten
- Neue Objekte erstellen, bestehende nicht bearbeiten
- Vorhandene Objekte bearbeiten, keine neuen Objekte erstellen
Beim Attributmapping können auch Modifizierungen der Quelldaten vorgenommen werden. Für jede Feld-Zuordnung kann eine Callback-Funktion angegeben werden, die beispielsweise Zeichenoperationen und Berechnungen auch auf Basis mehrerer importierter oder im aktuellen Objekt bereits vorhandener Attribute durchführt.

Data Director Video
Hier sehen Sie den Vortrag unseres Tribe Leads Jan Walther über den Pimcore Data Director anlässlich der Pimcore Inspire 2021.
Pimcore-Tutorials zum Data Director
In unserer Knowledge Base finden Sie eine Reihe von Video-Tutorials, die die Möglichkeiten des Pimcore Data Directors ausführlich erklären.

Testen Sie den Pimcore Data Director
Fordern Sie einen kostenlosen Login zu unserer Data Director Demo an. Vollziehen Sie unsere Videotutorials nach, testen Sie den Data Director mit Ihren eigenen Daten. Die Demo-Installation wird alle 24 h zurückgesetzt.
Vorteile gegenüber eigener Import-Implementierung
Performance: Daten werden nur importiert, wenn sich seit dem letzten Import nichts geändert hat, wenn sich beim Import ein Objekt nicht geändert hat, braucht es nicht gespeichert werden
Flexibilität: Importe sind individuell an die Datenquelle und Ihr Pimcore-Datenmodell anpassbar;
Importieren aller Pimcore-Objekte inkl. Daten-Objekte, Objektbausteine, Feldsammlungen, Assets und Dokumente
Minimierung des Programmieraufwandes: einzig bei Datenmodifizierungen aus der Datenquelle muss minimal programmiert werden
Komfort-Funktionen: z.B. Optimierung der Vererbung, Zurücknehmen von Importen, Ersetzen von Platzhaltern
Aktualität: Profitieren Sie durch Bitbucket-Zugriff (kostenpflichtig) von der kontinuierlichen Weiterentwicklung des Data Directors
Weitere Highlights im Überblick
Dateibasierte Importe
(Überwachung eines Verzeichnisses und automatischer Import bei neuen Dateien), z.B. für:
- automatische Asset-Importe in Pimcore (z.B. von einem Netzlaufwerk)
- automatische Zuordnung von Assets zu Pimcore-Objekten anhand des Dateinamens
Import mehrerer Dateien
(CSV, XML, Excel) aus einem Quellverzeichnis mit automatischer Deduplizierung
Import von einer URL als Datenquelle
Import von Daten aus Pimcore-Objekten:
- Migration der Daten von einem Objektfeld zu einem anderen ohne Datenverlust
- dynamische Massendatenbearbeitung, die im Pimcore-Grid nicht möglich ist (z.B. Preise um 10% erhöhen)
Import von Dokumenten (Befüllung der Editables)
Starten von Importen per REST-API
Generieren von Antwortdokumenten, z.B.
- Erfolgsstatus der importierten Objekte
- Aufzeichnen von Import-Fehlern
- Aufrufen eines anderen Imports, der vom aktuellen Import abhängig ist
- Erstellen von CSV-, XML-, JSON-Dokumenten, die von anderen Systemen als Importquelle verwendet werden können
- Antwortdokumente für single-page applications/PWA frontend requests
Überspringen von Datensätzen aus der Importquelle
(z.B. wenn Daten fehlen oder deren Qualität ungenügend ist)
Einfacher Import von Relationen
Import von Objekthierarchien/Objektbäumen
- Angabe des Elternelementes möglich
- Option zur Optimierung der Vererbung (Daten werden so weit oben in der Objekthierarchie eingetragen wie möglich)
Übersetzung von Texten (per DeepL oder AWS API)
Unterstützung sämtlicher Pimcore-Datentypen (inkl. Relationen mit Metadaten, Objektbausteinen, Feldsammlungen usw.):
Optimierte Performance:
- falls sich die Quelldaten nicht geändert haben, kann der Import des Datensatzes übersprungen werden
- falls im Import Daten eines Objektes nicht geändert werden, braucht dieses nicht gespeichert werden
Möglichkeit Importe zurückzunehmen:
- Falls sich ein Fehler bei der Attributzuordnung eingeschlichen hat und dadurch ggf. mehrere Tausend Objekte mit falschen Daten befüllt wurden, kann die Änderung zurückgespult werden – es werden in diesem Fall nur die im Import gemappten Felder zurückgenommen, nur bei den im Import veränderten Objekten – ein großer Vorteil gegenüber des Einspielens eines Komplett-Backups
Wie dies alles genau funktioniert, sehen Sie auch in unserer Dokumentation